모니터링의 필요성
저는 최근 홈서버를 통해 블로그를 운영중입니다.현재의 사이트가 그 블로그이죠.
제 블로그는 이상하게도 자주 404에러가 발생하고 있었습니다. 블로그 외의 다른 서비스들을 많이 띄워놨지만 다른 서비스들은 아무 문제가 없었습니다.
처음에는 막연히 설정을 살펴보며 원인을 찾으려 했지만 실패했고, 보다 명확한 원인 분석을 위해 모니터링 도구를 도입하게 되었습니다.
CPU, Memory, Disk 등의 리소스 사용량을 확인하기 위해 Grafana + Prometheus + Node Exporter 구성을 도입했지만, 리소스는 충분했고 병목이 발생할 만한 지점은 보이지 않았습니다. 이후, Weave Scope를 추가해 컨테이너 및 프로세스를 시각화하며 원인을 계속해서 추적했습니다.
원인
Grafana에서는 이상 징후를 발견하지 못했지만, Weave Scope로 컨테이너와 프로세스를 시각화해보니 npm 관련 작업이 반복적으로 실행되고 있는 것을 확인할 수 있었습니다.
조치 이후 확인해봤을 때 조치 전후 CPU 사용량이 57% → 6%, I/O Usage Write도 최고치 38MB/s → 4kB/s로 많은 차이가 있지만, 정상 상태에서의 사용량을 몰라 현재 상태에 이상이 있다는 걸 몰랐습니다.
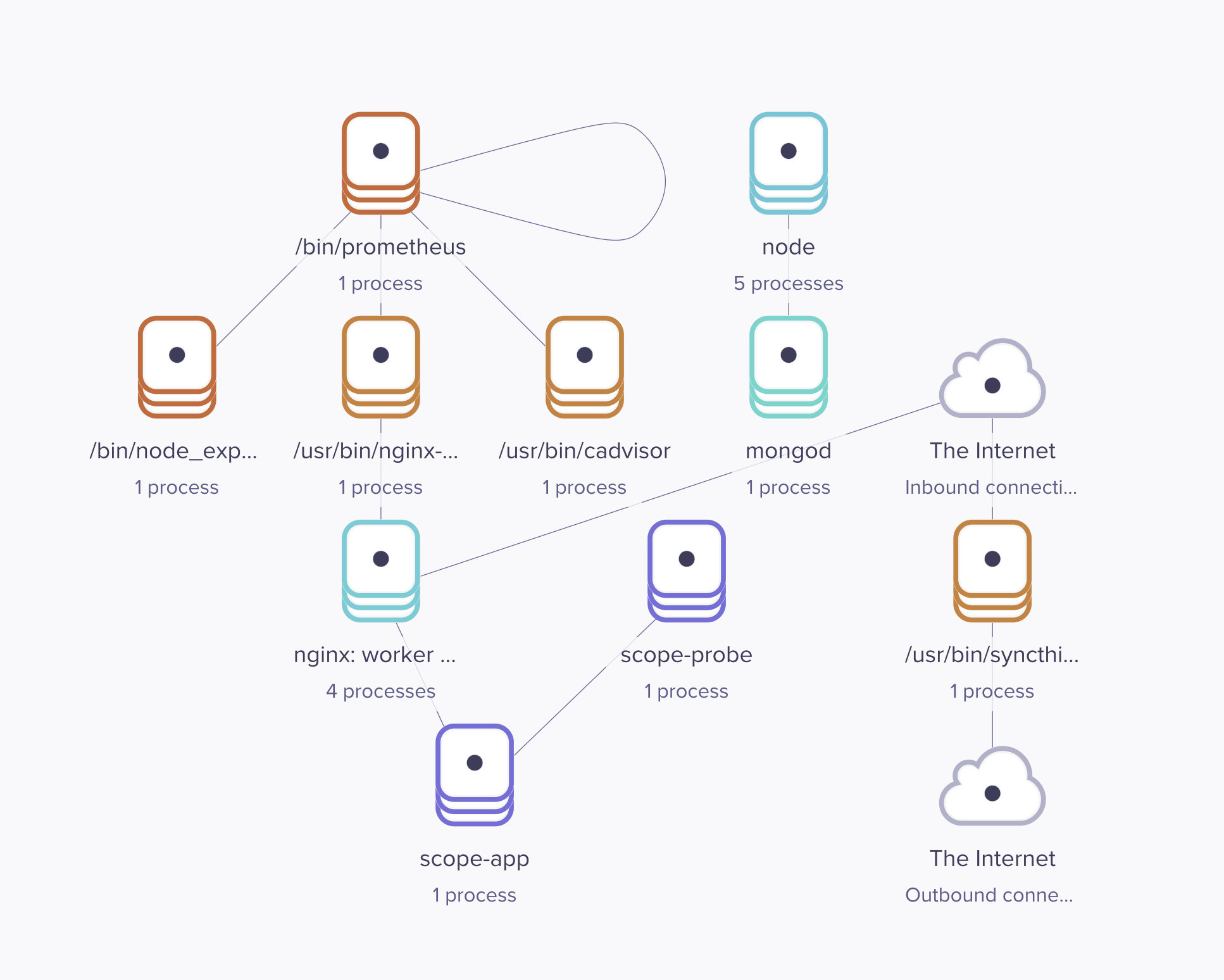
문제 상황에 찍어놓은 이미지가 없어져서 정상 상태 이미지로 대체합니다.
아래는 제 블로그 docker compose 파일의 일부입니다.
services:
quartz:
image: node:22-slim
container_name: quartz
restart: unless-stopped
volumes:
- type: bind
source: /your/path/to/quartz/build
target: /usr/src/app
- type: bind
source: /your/path/to/quartz/content
target: /usr/src/app/content
- type: bind
source: /your/path/to/quartz/public
target: /usr/src/app/public
working_dir: /usr/src/app
command: sh -c "npm ci && npx quartz build"
blog:
image: joseluisq/static-web-server:2-alpine
container_name: blog
ports:
- 8349:80
restart: unless-stopped
environment:
- SERVER_ROOT=/var/public
- SERVER_CONFIG_FILE=/etc/config.toml
volumes:
- type: bind
source: ./public
target: /var/public
- type: bind
source: ./etc
target: /etc문제가 되고 있던 부분은 quartz 서비스의 restart: unless-stopped 부분이었습니다.
quartz 서비스의 역할은 정적페이지로 빌드를 해주는 것인데 해당 동작이 끝나고 컨테이너가 종료되었을 때, restart 정책에 의해 자동으로 재시작이 계속 되어 빌드를 계속하고 소스를 갈아끼우는 동안 연결이 되지 않아 주기적으로 404에러가 발생하고 있는 것이었습니다.
처음 개발 당시엔 npx quartz build --serve로 띄워두었기에 인지하지 못하고 있던 부분이었습니다.
조치
저의 경우엔 quartz 서비스의 restart 정책을 주석처리하였습니다.
블로그 서비스의 서빙을 위해 blog 서비스를 따로 띄워두었기에 npx quartz build --serve로 바꿀 필요도 없었고, 일회성으로 빌드하도록 수정하였습니다.
배운 점
docker compose의 restart 정책에 대한 이해가 부족했음을 깨달았고, 모니터링의 중요성을 새삼 깨달았습니다.
지속적인 불편함이 있었지만 원인을 찾지 못하고 있었는데, 모니터링을 달자마자 거의 바로 원인을 찾게되어 원래도 중요시했지만 더욱더 믿음이 올라갔습니다.
restart 정책 요약
no: 컨테이너가 종료되어도 재시작하지 않음
always: 항상 재시작
unless-stopped: 사용자가 멈추지 않는 한 재시작
on-failure: 에러 코드 반환 시에만 재시작
댓글 (0)